"AI가 스스로 학습하고, 경험을 통해 더 똑똑해진다면?" 바로 이 개념이 강화 학습(Reinforcement Learning)의 핵심입니다!
AI가 바둑을 배우고, 로봇이 장애물을 피해 움직이며, 자율주행 자동차가 도로에서 스스로 길을 찾는 것—이 모든 것이 "강화 학습" 덕분이라는 사실, 알고 계셨나요? 강화 학습은 인공지능이 시행착오를 거듭하며 최적의 행동을 찾아가는 학습 방식입니다. 특히 최근 AI 기술 발전과 함께 더욱 주목받고 있죠. 이 글에서는 강화 학습이 무엇인지, 어떻게 작동하는지, 그리고 실제 사례를 통해 AI가 어떻게 스스로 학습하고 진화하는지 살펴보겠습니다. 복잡해 보이지만, 쉽게 이해할 수 있도록 풀어서 설명해 드릴게요. 끝까지 함께 읽어주세요!
📋 목차
AI 강화 학습이란? 기본 개념 정리
강화 학습(Reinforcement Learning, RL)은 인공지능이 환경과 상호작용하며 시행착오를 통해 최적의 행동을 학습하는 방법입니다. 쉽게 말해, 마치 아이가 처음 자전거를 배우듯, AI도 여러 번 시도하고 피드백을 받으며 점점 더 나은 성능을 내도록 학습합니다. 강화 학습의 핵심 개념은 보상(reward)입니다. AI는 특정 행동을 수행할 때 보상을 받을 수도 있고, 반대로 불이익을 받을 수도 있습니다. 이러한 경험을 바탕으로 AI는 최상의 결과를 얻기 위한 전략을 점진적으로 개선해 나갑니다. 강화 학습은 다양한 분야에서 활용됩니다. 예를 들어, 체스나 바둑 같은 게임에서 인간 챔피언을 이긴 AI, 자율주행 차량이 복잡한 도로에서 최적의 경로를 찾는 기술, 그리고 로봇이 스스로 균형을 잡고 이동하는 방법까지—all 강화 학습의 응용 사례입니다.
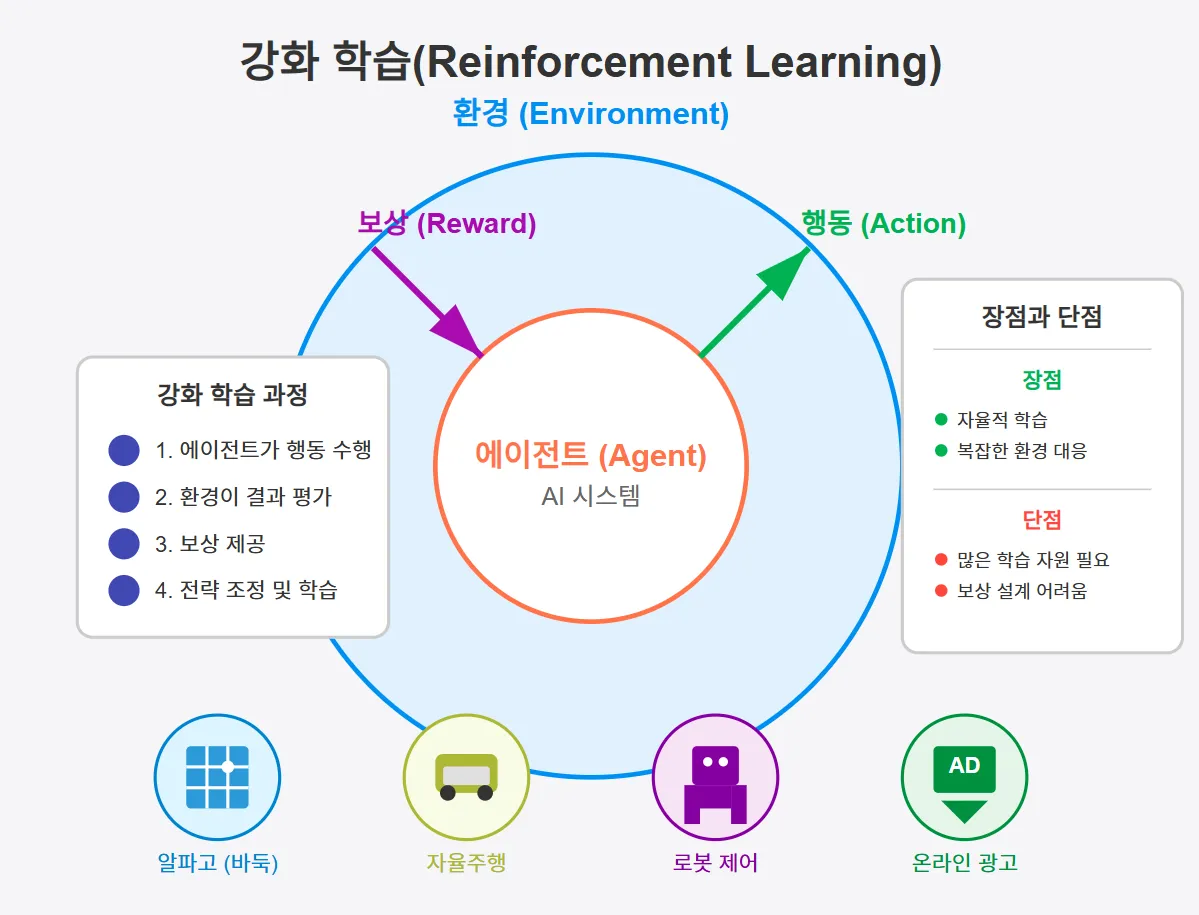
AI 강화 학습의 주요 구성 요소
강화 학습이 어떻게 작동하는지 이해하려면 그 구성 요소를 살펴봐야 합니다. 기본적으로 강화 학습은 다음과 같은 네 가지 핵심 요소로 이루어집니다.
| 구성 요소 | 설명 |
|---|---|
| 에이전트 (Agent) | 강화 학습을 수행하는 주체(AI 시스템)로, 환경에서 행동을 수행합니다. |
| 환경 (Environment) | 에이전트가 상호작용하는 공간이며, 보상과 결과를 제공합니다. |
| 행동 (Action) | 에이전트가 환경에서 수행할 수 있는 선택지입니다. |
| 보상 (Reward) | 에이전트의 행동 결과에 따라 제공되는 피드백으로, 목표를 향해 나아가도록 유도합니다. |
AI 강화 학습은 어떻게 작동할까?
강화 학습은 단순한 개념이지만, 실제로 작동하는 방식은 여러 단계로 이루어집니다. 다음은 강화 학습이 진행되는 일반적인 과정입니다.
- 에이전트가 초기 상태에서 무작위로 행동을 수행합니다.
- 환경이 행동의 결과를 평가하고 보상을 제공합니다.
- 에이전트는 보상을 바탕으로 학습하고 행동 전략을 조정합니다.
- 이 과정을 반복하면서 최적의 행동 패턴을 찾아냅니다.
예를 들어, 자율주행 차량이 처음에는 교통 신호를 무시하거나 장애물에 부딪힐 수도 있지만, 점진적으로 올바른 운전 방법을 학습하면서 더 나은 주행 능력을 갖추게 됩니다. 이러한 반복적인 학습 과정을 통해 AI는 점점 더 효과적인 결정을 내리게 됩니다.

실제 사례로 보는 강화 학습
강화 학습은 이론적으로만 존재하는 것이 아닙니다. 이미 우리 일상 곳곳에서 적용되고 있습니다. 다음은 실제 사례를 통해 강화 학습이 어떻게 활용되는지 살펴보겠습니다.
| 사례 | 설명 |
|---|---|
| 알파고 (AlphaGo) | 구글 딥마인드에서 개발한 AI로, 바둑을 학습해 인간 최고수를 이긴 사례 |
| 자율주행 자동차 | 도로 환경에서 최적의 주행 방법을 학습하며, 사고를 줄이는 기술 |
| 로봇 제어 | 로봇이 장애물을 피하고 최적의 움직임을 학습하는 기술 |
| 온라인 광고 최적화 | 사용자의 반응을 기반으로 최적의 광고를 보여주는 기술 |
AI 강화 학습의 장점과 단점
강화 학습은 매우 강력한 AI 학습 방법이지만, 모든 문제에 적합한 것은 아닙니다. 이를 이해하기 위해 장점과 단점을 비교해 보겠습니다.
- 장점: 자율적 학습이 가능하며, 인간이 직접 프로그램하지 않아도 최적의 솔루션을 찾을 수 있음.
- 장점: 복잡한 환경에서도 최적의 결정을 내릴 수 있는 능력이 뛰어남.
- 단점: 학습하는 데 많은 시간과 계산 자원이 필요함.
- 단점: 보상 시스템 설계가 어렵고, 잘못 설계하면 학습이 제대로 이루어지지 않을 수 있음.
AI 강화 학습의 미래와 전망
강화 학습은 앞으로 더욱 발전할 것으로 예상됩니다. 특히, 로봇 공학, 금융 트레이딩, 의료 진단 등 다양한 분야에서 혁신적인 변화를 가져올 것입니다. 몇 가지 예상되는 미래 트렌드를 살펴보겠습니다.
- 로봇 공학: 인간과 협업하는 지능형 로봇 개발 가속화.
- 의료: AI가 환자의 데이터를 분석하고 최적의 치료 방법을 학습.
- 금융: AI가 금융 시장의 패턴을 학습하여 투자 전략 최적화.
AI 강화 학습에 대한 자주 묻는 질문 (FAQ)
강화 학습은 환경과 상호작용하며 최적의 행동을 학습하는 방법이고, 지도 학습은 정답이 주어진 데이터로 학습하며, 비지도 학습은 정답 없이 패턴을 찾는 방식입니다.
대표적인 사례로는 알파고(AlphaGo), 자율주행 자동차, 로봇팔 학습, 온라인 광고 최적화 시스템 등이 있습니다.
확률과 통계, 미적분, 선형대수, 프로그래밍(Python 추천), 머신러닝 개념 등이 필요합니다.
주로 Python 기반의 TensorFlow, PyTorch, OpenAI Gym, Stable Baselines3 같은 프레임워크를 사용합니다.
보상 설계가 까다롭고, 학습 과정이 많은 연산을 필요로 하며, 시행착오 과정이 길기 때문입니다.
로봇, 의료, 금융, 게임 등 다양한 분야에서 발전 가능성이 크며, 보다 효율적인 학습 알고리즘이 연구되고 있습니다.
마무리 및 정리
강화 학습은 AI가 환경과 상호작용하며 스스로 학습하는 강력한 방법입니다. 시행착오를 통해 최적의 행동을 찾아내는 이 방식은 이미 게임, 로봇, 자율주행, 금융 등 다양한 분야에서 활용되고 있습니다. 하지만 높은 계산 비용과 보상 설계의 어려움은 해결해야 할 과제입니다. 미래에는 더 효율적인 강화 학습 알고리즘이 개발되며, 더욱 현실적인 문제 해결 능력을 갖춘 AI가 등장할 것입니다. 강화 학습의 원리를 이해하고 응용하면, AI 기술의 발전을 보다 깊이 있게 경험할 수 있을 것입니다.
딥러닝 알고리즘의 종류와 활용
딥러닝 알고리즘의 종류와 활용되고 있는 분야에 대해 알아보도록 하자. 목차 1) 심층 신경망 (DNN, Deep Neural Network) 2) 합성곱 신경망 (CNN, Convolutional Neural Network) 3) 순환 신경망 (RNN, Recurrent Neural Net
engineer-daddy.co.kr
'Learn > 과학공학기술' 카테고리의 다른 글
| 전문가 혼합 모델(MoE): AI 모델의 새로운 혁신 (0) | 2025.03.20 |
|---|---|
| AI 모델 학습에서 지식 증류(Knowledge Distillation)의 역할과 활용법 (0) | 2025.03.19 |
| 검색 증강 생성(RAG) 기술: AI 혁신의 핵심 (2) | 2025.03.19 |
| AI 스케일링: 더 똑똑한 인공지능을 만드는 3가지 방법 (0) | 2025.03.19 |
| 전자약과 웨어러블 의료 기기의 융합: 미래 의료 혁신 (0) | 2025.03.18 |



